How to build your own AI for your business
•
Elliot Tikhomirov

What AI tools for business do you need?
If you haven’t yet heard of ChatGPT or other large language models (LLMs), I’d argue you’ve been living under a very large rock. In recent years the use of AI systems has exploded due to the now general-purpose, generative AI models.
Businesses can now use these tools to analyse financial documents, generate and error-correct code, create imagery, write content, interface with customers and a lot, lot more. It would appear that most businesses are now trialing the use of these systems and wondering how they can be used to increase efficiency within their own specific use case. Along with this quest for efficiency and productivity, comes rational fears… “What happens to my data? How will these tools speak to my customers? Could competitors somehow access my information? Will these tools disrupt my business model?” These are reasonable things to ask.
The answer to these questions is complicated and unique to your own situation. However, in this article I will aim to lift the veil on what these systems are, how they work and also how you and your team can practically integrate AI tools for business based on your own data.
Let’s start with the stack. First up, choosing your LLM.
A typical LLM-application stack consists of multiple layers of increasing specialisation. The first thing you need is an LLM itself (large language model). From the standpoint of a user, an LLM can be viewed as a black-box function that takes and outputs text, attempting to complete the input using the information in the context window and the data the model has been trained on.
The most common scenario is using a managed LLM hosted by companies like OpenAI and Anthropic, accessing them via an API (application programming interface). This is the fastest method, but requires you to send your data to these companies for use, and depending on your standards might not be an option.
There is another way though, and that is to self-host your own model using an open-source LLM like LLaMA (note: LLaMA is not an open-source solution in a conventional sense since the training set is not available to the public).
Either way, once you have chosen your model, it then needs to be exposed as a service endpoint. In the case of managed models, the cloud provider does it for you, providing an HTTP endpoint or a websocket for interacting with the model. Otherwise you’ll need to set up a server that would expose the model to other parts of your system. Runtimes like Ollama automatically create a lightweight server for your model; however, you still need to provision appropriate auto-scaling and load balancing.
Now you would think from here you can just start sending your chosen LLM queries… However, typically, you don't send queries to the LLM directly because the inputs need to be optimised to ensure that the model returns the most relevant and accurate answer. Simply providing raw text input to the LLM likely won’t yield the desired results, as the model's performance heavily depends on how the input is structured and framed. So what else do we need?
Well the next part of the stack you'd want to have is an abstraction layer that allows you to seamlessly integrate the LLM with other components of a broader ecosystem, such as vector databases, prompt analytics tools, and ready-to-use tools or plugins. These are commonly called orchestrator frameworks. This abstraction layer facilitates the integration of various components, which allows you to leverage their combined capabilities and create more sophisticated and powerful applications. The whole is greater than the sum of its parts as they say.
Suitable examples of these orchestrator frameworks include Langchain or Semantic Kernel. As mentioned, these frameworks act as an intermediary layer between the LLM and the other components, providing a unified interface and a set of tools and abstractions for building more complex LLM-based applications.
So let’s choose Langchain as our orchestrator framework in this example. Langchain offers connectors to the majority of popular LLMs, allowing you to easily integrate different models into your application. It also provides abstractions for building popular patterns and techniques, such as:
Meta-prompts: This technique involves injecting a system prompt with every input to the LLM, providing additional context or instructions that can guide the model's output. Think of meta-prompting as adding an extended prompt before every prompt to guide output.
Retrieval-Augmented Generation (RAG): This approach extends the model's context by integrating it with a vector database. The vector database is used to retrieve relevant information based on the input, which is then provided to the LLM along with the original input, allowing the model to generate more informed and context-aware responses. Think of RAG as giving the LLM an additional, different, brain to improve context and output.
In addition to these options, Langchain also supports integrations with various other components, such as document loaders, text splitters, and vector stores, enabling you to build end-to-end solutions for tasks like question answering, summarization, and text generation.
By leveraging orchestrator frameworks like Langchain or Semantic Kernel, you can abstract away the complexities of integrating and managing various components, enabling you to focus on building innovative applications that leverage the full potential of large language models and other complementary technologies.
Do you self-host or not?
So now that we have a chosen LLM and an orchestrator framework to assist in generating the outputs we want, the next most important consideration is what trade-off we want between model performance and computational feasibility. Generally, larger models (the number of parameters) tend to produce higher-quality responses, but they also require more computational resources and are more expensive to host. For instance, models like GPT-4, with its trillions of parameters, necessitate specialised server hardware for hosting and inference. So if your primary objective is to achieve the best possible performance, you may need to be satisfied with managed models offered as APIs through cloud services such as Azure OpenAI and Amazon Bedrock.
However, there may be scenarios where you are dealing with sensitive data and would prefer to have full control over the deployment environment of your LLM. In this case, self-hosting an off-the-shelf model might be the option you require. While generative models tend to perform better with a larger number of parameters, certain smaller specialised fine-tuned models can outperform general-purpose models on their dedicated set of tasks.
Table 1 below shows the off-the-shelf models with permissive licences that can be self-hosted. To understand the scale of each of the presented models, note that GPT-3.5 is a general-purpose model with 175 billion parameters, while GPT-4 has 1.76 trillion parameters. The memory requirements are shown in Mac-specific unified memory architecture. NVIDIA GPUs have roughly 2x memory bandwidth in consumer models and up to 10x in data-centre grade models, allowing them to run these models with less VRAM.
ModelModalityNumber of ParametersModel SizeMemory Requirements (at 30 tokens / second)Use-casePerformance LevelLlama 3 8B(4-bit quantized formats)Text8 billion4.7 GB4 GB Unified RAM / RequestGeneral usage, server-hosted< GPT-3.5Llama 3 70B(4-bit quantized formats)Text70 billion40 GB40 GB Unified RAM / RequestGeneral usage, server-hosted~ GPT-3.5Phi-3Text3.8 billion2.3 GB2 GB Unified RAM / RequestGeneral usage, embedded< GPT-3.5ChatQA-1.5 8BText8 billion4.7 GB4 GB Unified RAM / RequestRAG, server-hosted<= GPT-4 (RAG)
Microsoft’s Phi-3 and Nvidia’s ChatQA-1.5 provide the best balance between size and performance, making them suitable for self-hosted use-cases.
So let’s say you require self-hosting. From here, these models can be self-hosted in 3 distinct ways:
Option 1: The model is self-hosted in the cloud
Self-hosting in the cloud eliminates the risk that your data is being used for any form of training with other providers. You could provision an instance on EC2 to support such models (e.g., g5g.xlarge with 16 GB of VRAM) and it would cost around AUD $568 per month to serve 10-20 concurrent requests per second. This may be feasible for high-value scenarios where the model has to process PII or needs to be fine tuned on a specialised dataset.
Option 2: On-prem deployment
This scenario allows organisations to achieve the same result as Option 1 while saving on hardware costs. The models can be deployed in a self-managed, GPU-enabled server running a load-balanced Kubernetes (K8S) cluster in house, as shown in the diagram below:
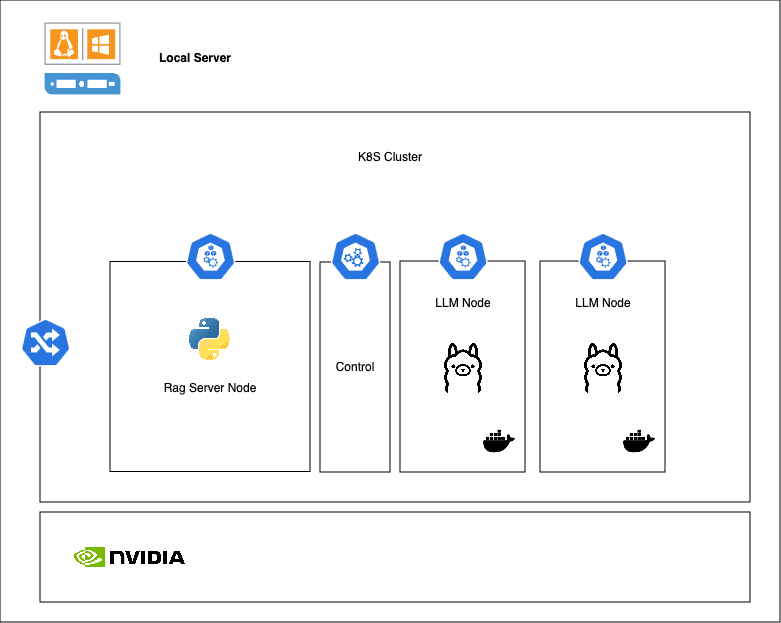
Load-balanced Ollama nodes can be deployed using K8S with an additional node used for running a RAG server that uses LangChain (Python) or Semantic Kernel (C#). And depending on an expected load, a machine can be configured with comparable specs to g5g.xlarge using 128 GB of RAM and 16 gb VRAM (RTX4080) with an upfront cost of around $5000 (as of July 2024). Such machines would need to be configured with Linux for better virtualisation support.
This setup will be able to serve 10-20 concurrent requests per second at 30 tokens/second (compared to 100 tokens/second in GPT3.5). The main challenge with setting up horizontal scaling is requiring substantial knowledge of devops and kubernetes for proper scalability. This deployment model can be suitable for admin-side applications with a limited number of users dealing with highly sensitive data. However, this cannot be used for a direct deployment of the model in consumer-facing apps.
In short, it’s reasonably cost effective, however less capable and limited in its use cases.
Option 3: A desktop app
Optimised small-sized models such as Phi-3 are a viable option for integration in macOS, iPadOS, and Windows apps. Such models could be used for local RAG use cases or for transforming unstructured data into semi-structured formats (e.g., natural language shortcuts). For instance, an email client equipped with an optimised language model could automatically categorise incoming messages, suggest relevant replies, and draft emails based on user preferences. This scenario becomes especially powerful if the models are combined with OCR or other more specialised ML models. One can easily imagine the benefits for productivity apps and/or admin dashboards with direct access to either remote data via an exposed API endpoint or local on-device data.This would work as per the table below.
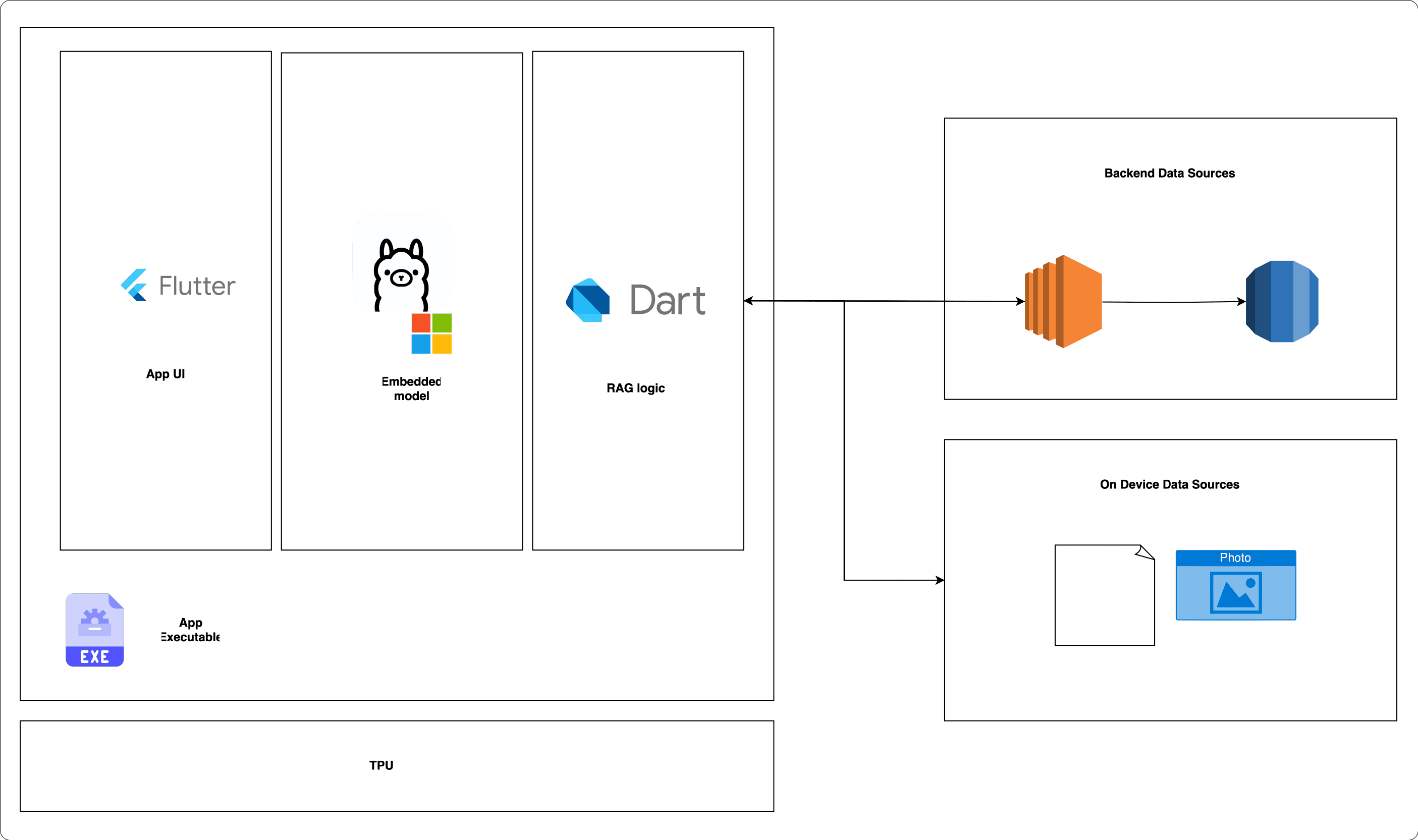
Note: Due to their relatively large size and lower performance, it's currently challenging to integrate an LLM (Large Language Model) with a modal app in a similar manner. For mobile-first scenarios, it's advisable to utilise built-in models such as Gemini Nano, which are specifically designed for mobile devices and offer better performance and compatibility.
Now we have our stack. What’s next… Fine-tuning or Retrieval-Augmented Generation
With your chosen stack deployed, you’re likely now wondering how you start to collate and feed your own data to this system to start to reap the benefits. Well as previously mentioned the simplest approach is to include all relevant data in the context with each request. This approach does not require any additional training or retrieval system:
However, it’s not really viable for many users as it can be limited by the maximum context length that the language model can handle, and it may not be suitable for applications that require access to a vast amount of knowledge or frequently updated information.
So let’s start with RAG. The Retrieval-Augmented Generation (RAG) approach combines a pre-trained language model with a retrieval system, allowing the model to access and incorporate external knowledge sources during inference. This approach can be particularly useful for advanced semantic querying, where the model needs to reason over a broad range of topics or domains. For example, you can submit the past 5 years' financials in whatever format pleases you and start to train your RAG specifically on this data for queries.
And it’s surprisingly simple to implement using Langchain and Ollama. In this example we use FAISS as a vector DB, however you more likely to use pgvector or CosmosDB in a real application:
Your orchestrator service (Langchain in our case) integrates with a chosen vector database and finds documents that match the query. Then, your chosen language model attempts to formulate the response based on the content of these documents and the input query. In such a case, you rely on the model's reasoning, but not directly on the training set of the model, making the responses more contextually accurate:
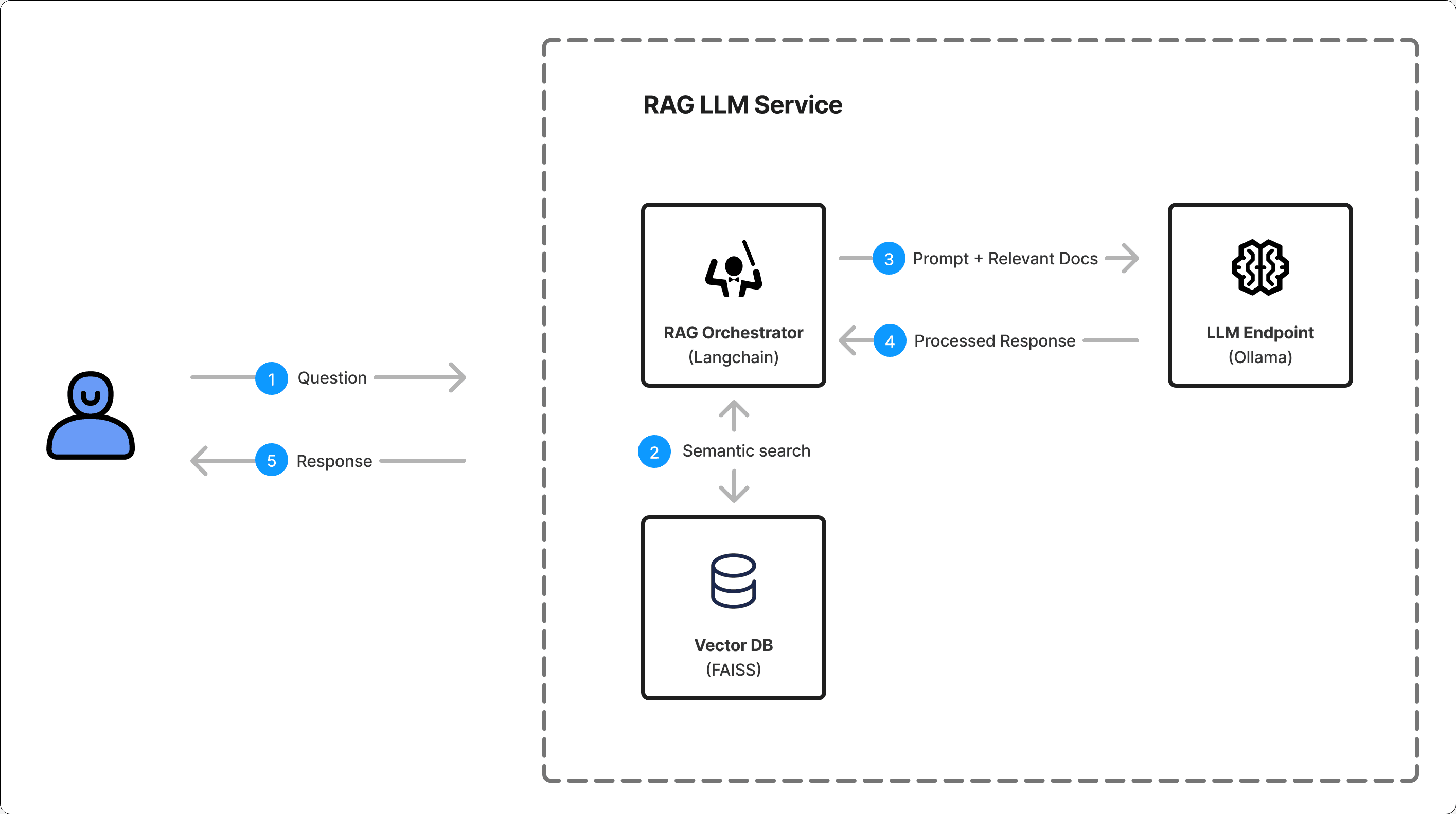
Unlike fine-tuning, the RAG approach does not require additional training data, as the language model is already pre-trained, and the retrieval system can be populated with any relevant knowledge sources, such as websites, databases, or document repositories. This makes the RAG approach more flexible and scalable, as the knowledge base can be easily updated or expanded without the need for retraining the language model.
The advantage of this is that the RAG approach decouples the language model from the knowledge base, allowing for a stateless model that can be easily deployed and scaled across multiple instances or environments. This can be particularly advantageous for large-scale applications or services that require high availability and low latency. It even allows you to swap out your chosen LLM in future and retain your knowledge base within the RAG.
Ok so that’s RAG. What about fine-tuning an existing model?
Fine-tuning a large language model involves further re-training the model on a specific domain or task, using a curated dataset relevant to that domain or task. This approach can be beneficial when dealing with sensitive data or specialised reasoning requirements that the original model may not have been optimised for. However, fine-tuning requires a substantial amount of labelled data, often in the range of thousands or even millions of examples, which can be costly and time-consuming to obtain.
Fine-tuning can be particularly advantageous when working with sensitive data, such as personal information, medical records, or confidential business data. By fine-tuning a relatively small model on an organisation's proprietary data source, it can become a great source of competitive advantage, with superior speed and reasoning capabilities for the specialised domain. This approach allows organisations to leverage their sensitive and confidential data to create a powerful, domain-specific model tailored to their unique needs, without the risk of inadvertently leaking or using that data for training purposes.
A fine-tuned model can provide highly accurate and efficient reasoning, analysis, and decision-making within the specialised domain, giving the organisation a significant edge over competitors relying on general-purpose models.
One way you can prototype a fine-tuned model is by using Azure OpenAI Service. First, you prepare your training and validation datasets in a json format supported by GPT-API:
Then you can use Azure Open AI python SDK to fine-tune your model:
When the fine-tuning job succeeds, the value of the fine_tuned_model variable in the response body is set to the name of your customised model. The new model will be available for deployment in Azure console or Azure CLI:
Wrapping it all up
As we’ve learnt, there is already a vast landscape of choice and complexity for selecting, implementing and deploying AI within your business. However, if you have followed along, you should now grasp the basic concepts of how to select and deploy a tailored system.
Whether you’re opting for managed APIs, self-hosting open-source models, or pursuing fine-tuning and retrieval-augmented approaches, you must carefully evaluate your specific requirements, data sensitivity, and performance needs. As this rapidly evolving field continues to advance, a pragmatic approach to architecting LLM-based solutions will be instrumental in harnessing the transformative power of language models while mitigating risks and optimising for long-term success.
At Adapptor we’ve got over 13 years of experience in mobile app development and more recently AI systems. If you are interested in learning how the deployment of such a system could benefit your business please reach out to us on 08 6381 9170 or email us at hello@adapptor.com.au.


